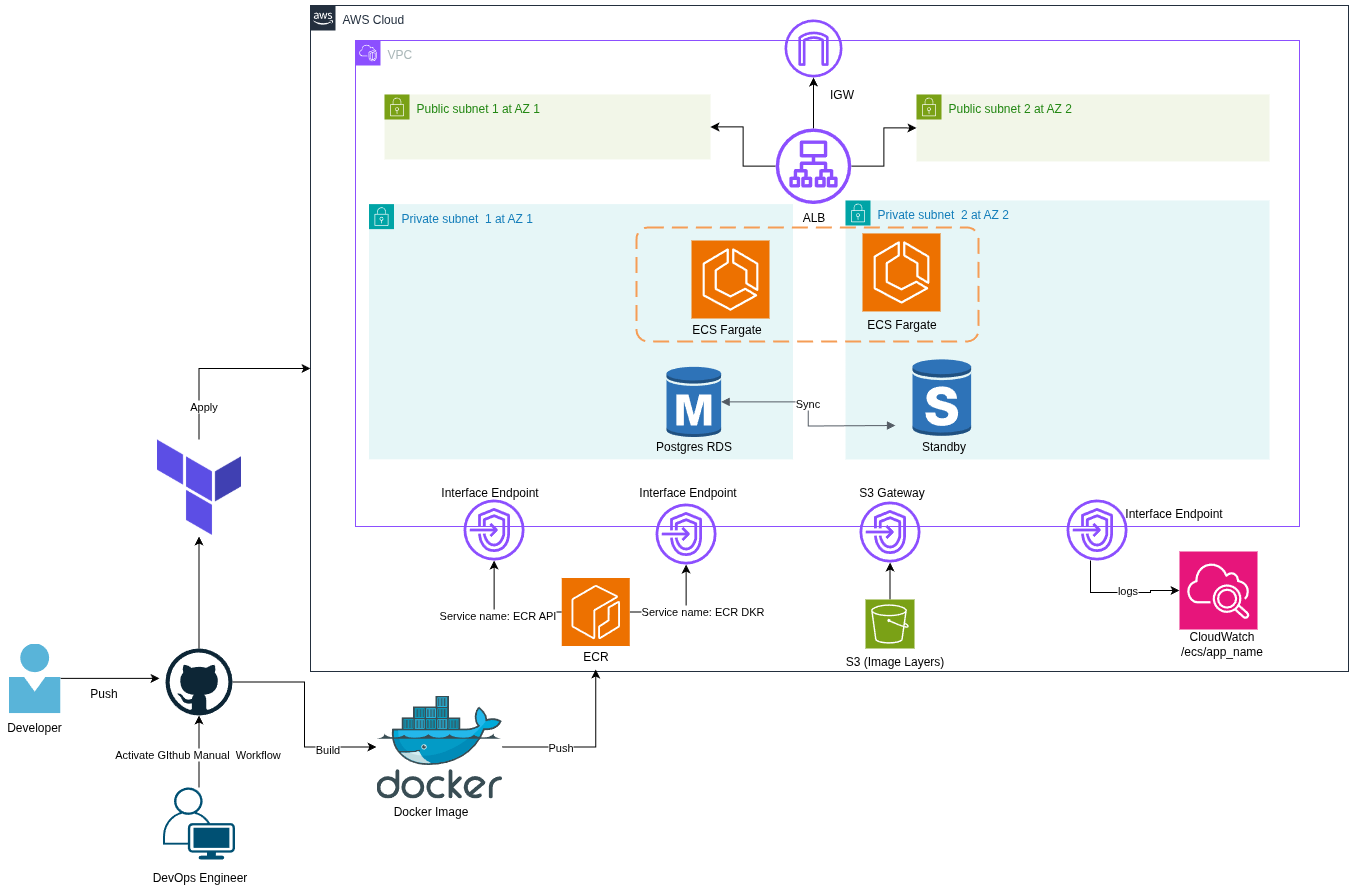
Security: No SSH, runs in private subnet, AWS-managed runtime.
Cost: Pay per vCPU and memory; slightly more expensive for long-running tasks than EC2.
HA: Automatically spans multiple AZs. Complexity: Easier to operate but less control over OS-level configs.
Security: Terminates HTTPS, handles SSL/TLS certificates securely.
Cost: \~$18–$20/month base + traffic costs.
HA: Regional service, auto-scales and load balances across AZs.
Complexity: Adds config overhead if using path-based routing or multiple target groups.
| | **VPC with Public/Private Subnets** |Security: Public ALB, private ECS tasks & RDS. Minimizes surface area.
Cost: No direct cost, but subnet design affects resource placement and networking choices.
HA: Subnets in multiple AZs for failover. Complexity: More complex Terraform code; requires careful design to avoid misconfiguration.
Security: Encrypted at rest & in transit; runs in private subnet.
Cost: \~$30–$40/month for dev size; production costs much higher.
HA: Multi-AZ failover, automated backups. Complexity: No OS-level access; bound to AWS maintenance windows.
Security: Logs sent privately via VPC endpoint.
Cost: \~$7.3/month for endpoint + $0.50/GB logs.
HA: AWS-managed; no single point of failure.Complexity: Needs careful retention management or costs can spiral.
# Public Route Table Configuration
resource "aws_route_table" "public_rtb" {
vpc_id = var.vpc_id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = {
Name = "${var.env}-public-rtb"
}
}
resource "aws_route_table_association" "public_subnet_assoc" {
count = 2
subnet_id = aws_subnet.public_subnet[count.index].id
route_table_id = aws_route_table.public_rtb.id
}
# Private Subnet Route table Configuration
resource "aws_route_table" "private_rtb" {
vpc_id = var.vpc_id
tags = {
Name = "${var.env}-private-rtb"
}
}
resource "aws_route_table_association" "private_subnet_assoc" {
count = 2
subnet_id = aws_subnet.private_subnet[count.index].id
route_table_id = aws_route_table.private_rtb.id
}